* 이 목록은 책 '파이썬으로 챗봇 만들기' 내용을 공부하며 정리한 글입니다.
1) 형태소 분석(POS Tagging)
사용자가 입력한 문장에 대해 이해를 빠르게 하기 위해 형태소를 분석한다.

- LEMMA: 처리되는 단어 형태
- POS: 단어의 품사
- TAG: 품사+추가정보(ex: 과거시제, 현재 시제)
- DEP: 문맥 간 의존도(토큰들 간의 관계)
- SHAPE: 단어의 형태(대소문자, 부호, 숫자 등)
- ALPHA: 알파벳 여부
- Stop: 불용어 여부(문장 내에서 크게 의미가 없는 단어)
2) 어간 추출과 표제어 추출
- 어간 추출: 단어를 잘라내고 남은 단어가 실제로 의미 있는 단어라고 생각하고 작업을 진행한다. → 단어의 의미를 내포한 핵심 부분이 제거되는 경우가 발생한다.
- 표제어 추출: 어휘 분석 및 형태 분석을 이용하여 조금 더 명확하게 추출한다. 의미 없는 부분만을 제거하고 표제어(lemma)라고 하는 단어의 사전적 형태만을 반환한다. 예를 들어 to buy, buying은 buy를 반환한다.
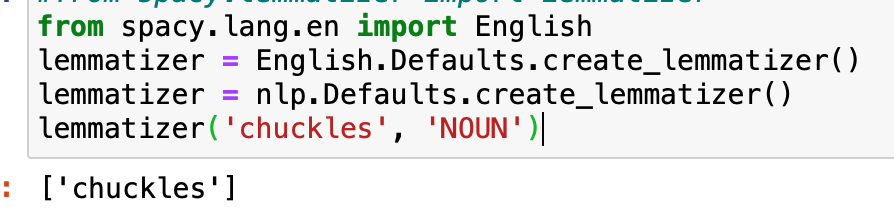
* 실습을 진행하였지만, 버전이 달라서인지 책에 나온 결과처럼 표제어가 제대로 추출되지 않았다.
3) 개체명 인식
- 주어진 문장에서 이름을 나타내는 개체를 찾아 기존에 정의된 범주로 분류한다. → 개체명 인식을 사용하면 주요 개체를 파악하여 질문의 맥락을 파악하는 데 많은 도움을 얻을 수 있다.

4) 불용어(Stop Words)
- a, an, the, to와 같이 빈번하게 사용되는 단어로 제거되길 희망하는 단어들

5) 의존 구문 분석
- 문장 경계 탐지에 사용 가능. 기본 명사 구문을 반복할 수 있다.
- 단어 사이의 부모 자식 관계를 설명하고, 단어가 발생하는 순서와 무관한 구문 분석 트리를 제공한다.
- 문법적으로 올바른 문장의 단어들 간의 관계를 찾을 수 있다.
- 문장 경계 탐지에 이용할 수 있다.
- 사용자가 두 가지 내용을 한 번에 말하고 있는지 확일할 때 매우 유용하다.

6) 명사 Chunks
- 어떤 고유한 명사를 설명할 수 있는 단어들의 집합

7) 유사도 확인
- 추천을 위한 챗봇을 구축할 때
- 중복을 제거할 때
- 철자 오류 확인 기능을 개발할 때

8) 토큰화
spacy는 토큰화를 띄어쓰기 기준으로 한다.

9) 정규 표현식
import re를 통해 한다.
개인적으로 spacy보다 Konlpy같이 한국어를 중점으로 다뤘으면 했는데 책에서 그러지 못해 아쉬웠다.
오타도 조금 있고 설명도 친절하진 않았다. 그래도 이 책은 자연어처리보다는 챗봇 만들기가 중점이니 그러려니 하고 다음 장을 기대하겠다.
'AI_ML' 카테고리의 다른 글
| 개체명 인식 (0) | 2021.07.21 |
|---|---|
| Seq2Seq (0) | 2021.07.15 |
| Introduction to Autoencoder (2) | 2021.03.25 |
| AutoRec: Autoencoders Meet Collaborative Filtering (0) | 2021.03.18 |
| DNN Recomendation 해설 및 정리 (0) | 2021.03.08 |