출처: https://www.youtube.com/watch?v=4DzKM0vgG1Y
1. 논문 핵심 요약
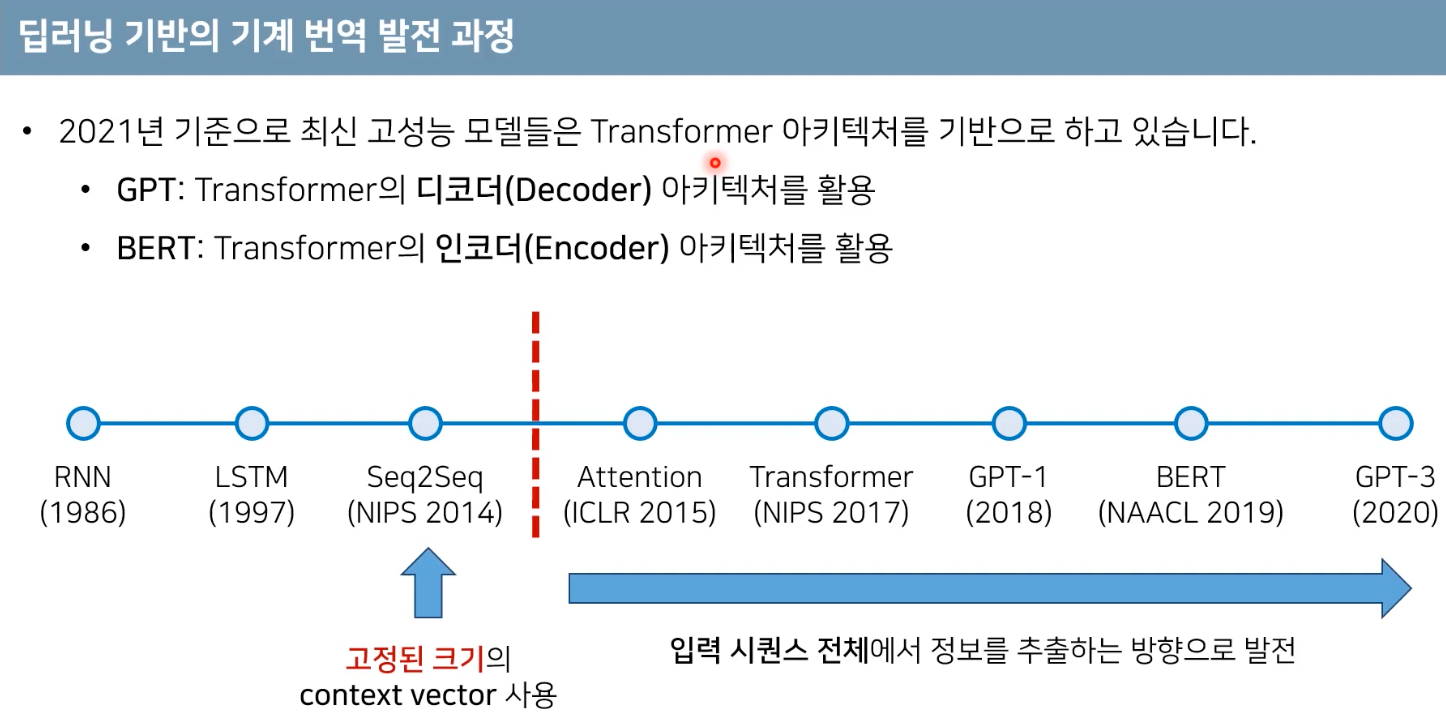
1.1 Sequence to Sequence: 한 시퀀스에서 다른 시퀀스로 번역.
- sequence란?
- sequence 하나의 문장으로 이루어져있다.
- 각각의 단어는 일반적으로 토큰으로 처리한다. --> 토큰들이 모인 것 = 시퀀스
- 딥러닝 기반 기계 번역의 축 (언어 번역 등)
- 인코더와 디코더로 구성
- 인코더: 번역을 하고자 하는 곳 처리. --> context vector를 만든다.
- 고정된 하나의 context vector에 문장에 대한 정보를 모두 담는다. 입력 문장에 대한 문맥 정보를 잘 담아야 된다. (일종의 bottleneck)
- 디코더: 고정된 크기의 context vector를 바탕으로 번역 대상 나라의 문장으로 번역하게 된다.

1.2 언어 모델 (Language Model)
- 언어 모델이란?
- 문자(시퀀스)에 확률을 부여하는 모델
- 언어 모델을 통해 특정한 상황에서의 적절한 문장이나 단어를 예측할 수 있다; 번역될 문장이 주어졌을 때 한국어로 나올 수 있는 문장 중 가장 확률이 높은 문장을 고른다.
- ex)
- 기계 번역: P(나는 너를 사랑해 | I love you) > P(나는 너를 싫어해 | I love you): 'I love you'라는 말이 주어졌을 때 '나는 너를 사랑해'가 나올 확률이 '나는 너를 싫어해' 보다 높다.
- 다음 단어 예측: P(먹었다 | 나는 밥을) > P(싸웠다 | 나는 밥을)
- 검색어 추천: 컴퓨터 공학을 치면 다음 단어 예측
- 하나의 문장은 여러개의 단어가 동시에 등장할 join probability와 같다. 예를 들어 친구와, 친하게, 지낸다가 같이 나올 확률과 같다.

- 통계적 언어 모델
- 전통적인 통계적 언어 모델은 카운트 기반의 접근으로 사용 > 현실의 모든 문장에 대한 확률을 가지려면 매우 많은 양의 데이터가 필요

- 시퀀스 자체가 학습 데이터에 존재하지 않으면 긴 문장을 처리하기 매우 어렵다. (0이 될 확률이 높다)
- 해결책: N-gram 언어 모델; 인접한 일부 단어만 고려. ex) ~밥을 먹었다 에서 '밥을'만 고려.
- 최근은 딥러닝 기반이 더 성능이 좋아서 쓰지 않는다.
- 전통적인 통계적 언어 모델은 카운트 기반의 접근으로 사용 > 현실의 모든 문장에 대한 확률을 가지려면 매우 많은 양의 데이터가 필요
1.3 전통적인 RNN 기반의 번역 과정
- 전통적인 초창기 RNN기반의 기계 번역은 입력과 출력의 크기가 같다고 가정한다.
- 입력과 출력에 단어의 개수가 T개로 같다고 가정
- h: 이전까지 입력되었던 데이터에 대한 전반적인 정보
- h0은 별도의 파라미터를 갖거나 초기화.

단점: 목적어와 서술어가 다른 경우 정확한 번역을 하기 어렵다. (그림처럼 '네가'를 통해 'miss'를 번역하기 어렵다)
> 이를 해결하기위해 seq2seq의 인코더가 고정된 크기의 context vector를 추출. 이후 context vector로 부터 디코더가 번역 결과를 추론.
1.4 RNN 기반의 Seq2Seq 자세히 살펴보기
- 인코더의 마지막 hidden state만을 context vector로 사용; 마지막 hidden state는 앞의 등장했던 모든 정보를 포함하는 벡터로 일종의 문맥 벡터로 볼 수 있다.
- 그런데 왜 RNN이 아니라 LSTM? > LSTM이 RNN보다 긴 dependency를 처리할 수 있어서.
- 인코더와 디코더는 서로 다른 파라미터(가중치)를 가진다.

- 기계 번역이 경우, 입력차원은 인코더와 디코더가 서로 다를 수 있다.
- 시퀀스를 시작할 때: sos (start of sequence), 끝날 때: eos (end of sequence)
- 단점: 고정된 크기의 context vector를 사용해서, 학습할 때 길이가 짧은 문장 들어오다가 테스트에서 긴 문장 들어오면 고정된 크기가 모든 정보를 표현할 수 없어서 성능이 떨어질 수 있다. > seq2seq이후 논문에서 해결된다.

(입력과 출력의 단어 개수가 T, T'으로 다를 수 있다.)

- LSTM은 RNN과 달리 출력으로 나오는 결과가 단순히 하나의 hiddens state가 아니라는 점이 다르지만, 기본적으로 동작하는 구조는 같다.
- 입력 문장의 순서를 거꾸로 한 이유: 앞쪽 정보가 줄어드는 경우가 많은데, 거꾸로하면 context vector에 주어부터 해서 앞 내용들을 더 를 더 잘 담을 수 있어서.
2. 논문 같이 읽기
Sequence to Sequence Learning with Neural Networks (https://arxiv.org/pdf/1409.3215.pdf)
- WMT'14 데이터셋 사용.
- LSTM을 총 4번으로 쌓았더니 좋은 성능.
- 영어 > 불어로 번역. 긴 문장도 잘 번역.
- BLEU라는 성능평가로 34.8 score (통계적 기계 번역은 33.3score, 딥러닝 기법 + 통계적 자연어 처리 기법: 36.5score가 나옴)
3. 코드 실습
파이토치:
텐서플로우:
'AI_ML' 카테고리의 다른 글
| 음악 장르 구분 + 추천 _ 오디오 분석 (0) | 2021.07.30 |
|---|---|
| 개체명 인식 (0) | 2021.07.21 |
| Introduction to Autoencoder (2) | 2021.03.25 |
| AutoRec: Autoencoders Meet Collaborative Filtering (0) | 2021.03.18 |
| spacy를 이용한 자연어처리 (0) | 2021.03.14 |