1. Collaborative Filering (CF)
- CF란?: 많은 유저들로부터 얻은 선호 정보를 이용해 유저의 관심사를 자동으로 예측하는 방법.
- 최종 목적: 유저 u가 아이템 i에 부여할 평점 예측
- CF의 방법: 유저-아이템 행렬 생성 -> 유저 or 아이템 간의 유사도 구하기 -> 주어진 평점과 유사도를 활용하여 비어있는 값(평점) 예측
- CF의 원리: 취향이 비슷한 유저들끼리 선호하는 아이템을 추천한다.
- CF의 종류:
- Neighborhood-based CF: User-based or Item-based
- Model-based CF: Non-parametric(KNN, SVD), Matrix Factorization, Deep Learning
- Hybrid CF: Content-baed Recsys과 결합
2. Neighborhood-based CF:
- UBCF (User-based CF): 유저 간 유사도를 구한 뒤, 유저와 유사도가 높은 유저들이 선호하는 아이템을 추천
- IBCF (Item-based CF): 아이템간 유사도를 구한 뒤, 타겟 아이템과 유사도가 높은 아이템 중 선호도가 큰 아이템을 추천.
- NBCF (Neighborhood-based CF):
- 구현이 간단하고 이해하기 쉬우나, 수가 늘어날 수록 확장성이 떨어지고, sparsity ratio가 99.5%이하여야된다.
- 99.5%가 넘으면 모델 기반 CF인 matrix factorization 활용 권장.
3. K-Nearest Neighbors CF
- 유저 가운데 타겟 유저와 가장 유사한 K명의 유저를 이요해 평점을 예측한다.
- Similarity measure:
- Mean Squared Difference Similarity
- Cosine Similarity
- Pearson Similarity (Pearson Correlation)
- Jaccard Similarity
4. Rating Prediction
- UBCF_Absolute Rating:
- Average: 다른 유저들의 타겟 아이템에 대한 rating을 같은 비중으로 평균을 낸다.
- Weighted Average: 유저 간의 유사도 값을 가중치로 사용하여 rating의 평균을 낸다
- UBCF_Relative Rating:
- 그런데, 유저가 평점을 주는 기준은 제각기 다르다. 그렇기에 그 편차(Deviation)를 사용하자.
- 모든 평점 데이터를 편차 값으로 바꾼 뒤 원래의 rating이 아닌 deviation을 예측.
- IBCF_Absolute Rating:
- Weighted Average
- IBCF_Relative Rating
- Top-N Recommendation: 예측 평점 계산을 높은 순으로 정렬하여 상위 N개만 뽑아 추천하기.
5. Model Based CF
- 항목간 유사성을 단순 비교에서 벗어나, 데이터에 숨겨진 유저-아이템 관계의 잠재적 특성/패턴을 찾는다.
- Paramettric ML을 사용, 주어진 데이터를 사용하여 모델을 학습하고 최적화를 통해 업데이트한다.
- NBCF는 유저/아이템 벡터를 데이터를 통해 계산된 형태로 저장하지만, MF CF는 유저, 아이템 벡터는 모두 학습을 통해 변하는 파라미터이다.
- 장점:
1. 학습된 모델로 추천해서 서빙 속도가 빠르다.
2. NBCF의 단점인 Sparsity, Scalability 문제를 개선한다.
3. Overfitting을 방지한다. (NBCF는 특정 주변 이웃에 크게 영향을 받는다.)
4. Limited Coverage 극복: NBCF 유사도 값이 정확하지 않으면 이웃의 효과를 보기 어렵다. - Latent Factor:
- 유저와 아이템 관계를 잠재적 요인으로 표현. (유저-아이템 행렬을 저차원 행렬로 분해)
- SVD, MF(SGD, ALS, BPR)
6. Singular Value Decomposition (SVD)
Rating Matrix R에 대해 유저와 아이템의 잠재 요인을 포함할 수 있는 행렬로 분해한다.

U: 유저 잠재 요인 행렬로 유저와 latent factor의 관계를 나타낸다.
𝛴 : 잠재 요인 대각행렬로 latent factor의 중요도를 나타낸다.
V: 아이템 잠재 요인 행렬로 아이템과 latent factor의 관계를 나타낸다.
한계점: 결측된 엔트리를 모두 채우는 imputation을 통해 dense matrix를 만들어서 SVD를 수행하는데, 정확하지 않은 imputation은 데이터를 왜곡시키고 예측 성능을 떨어트린다. (엔트리가 매우 적을 때 SVD 사용하면 과적합된다.)
7. Matrix Factorization (MF)
위 한계점을 바탕으로 SVD의 원리를 차용한 다른 접근 방법인 MF.
차이점: 관측된 선호도(평점)만 모델링하여 관측되지 않은 선호도를 예측하는 일반적인 모델 만들기.
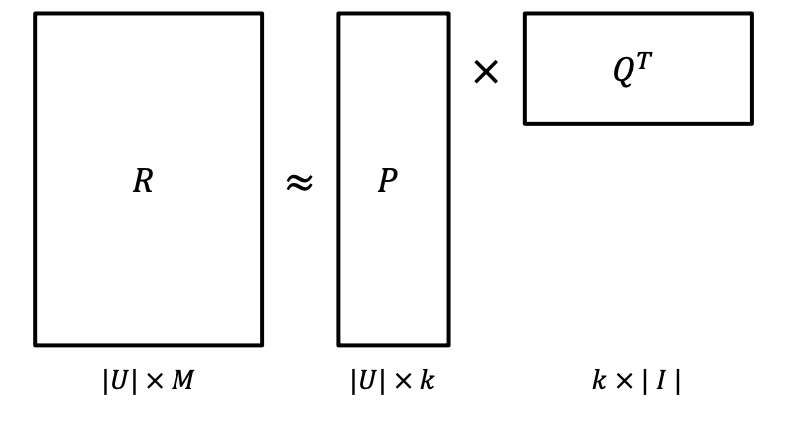
Rating Matrix인 R을 P와 Q로 분해하여 R과 최대한 유사하게 R^을 최적화한다.

MF + a: 기본적인 MF에 다양한 테크닉 추가하여 성능 향상시키기.
1. 전체 평균, 유저/아이템의 Biases를 추가하여 예측 성능 높이기. (평점을 짜게 주어 편향이 생길 수 있기에)

2. 신뢰도 추가하기: (모든 평점이 같은 신뢰도를 갖지 않을 수 있다: 대규모 광고, 평점이 정확하지 않을 때)

3. 시간 변화 추가하기: 시간에 따라 변화하는 유저, 아이템의 특성을 반영하고 싶을 때
8. MF for Implicit Feedback
Alternative Least Square (ALS)
- 유저와 아이템 매트릭스 중 하나를 상수로 놓고 나머지 매트릭스를 번갈아가며 업데이트하기.
- 대용량 데이터를 병렬 처리해서 빠른 학습이 가능.


- 유저 u가 아이템 i를 선호하는지를 binary로 표현한다.
- c_u,i로 유저 u가 아이템 i를 선호하는 정도를 나타내는 increasing function -> confidence를 표현.


9. Bayesian Personalized Ranking (BPR)
- 베이지안 추론에 기반, implicit data를 사용해 서로 다른 아이템에 대한 유저의 선호도를 반영.
- Personalized ranking이란?
- 유저가 item i보다 item j를 더 선호한다면 해당 정보를 MF의 파라미터에 학습 반영.
- 유저의 아이템에 대한 선호도 랭킹을 생성하여 이를 반영.
- 가정:
1. 관측된 아이템을 관측되지 않은 item보다 선호한다.
2. 관측된 아이템끼리는 선호도를 추론할 수 없다.
3. 관측되지 않은 아이템끼리도 선호도를 추론할 수 없다. - 최대 사후 확률 추정 (Maximum A Posterior)
- Bayes 정리에 의해, Posterior를 최대화 하면 주어진 유저 선호 정보를 최대한 잘 나타내는 파라미터를 추정할 수 있다.
- LEARNBPR이라는 Bootstrap 기반의 SGD를 활용해 파라미터를 업데이트한다.
- Matrix Factorization에 BPR Optimization을 적용한 결과 성능 우수하다.

'AI_ML' 카테고리의 다른 글
| [Boostcamp AI Tech] Recommender System with Deep Learning (0) | 2022.04.06 |
|---|---|
| [Boostcamp AI Tech] Item2Vec and ANN (0) | 2022.04.06 |
| [Boostcamp AI Tech] 추천 시스템 Basic(2) (0) | 2022.03.31 |
| [Boostcamp AI Tech] 추천 시스템 Basic(1) (0) | 2022.03.30 |
| VAE 기초 다지기_1 (0) | 2021.09.30 |