DNN Recomendation 해설 및 정리
이 글은 아래 사이트를 해설한 글이다.
developers.google.com/machine-learning/recommendation/dnn/softma
Deep Neural Network Models | Recommendation Systems
The previous section showed you how to use matrix factorization to learn embeddings. Some limitations of matrix factorization include: The difficulty of using side features (that is, any features beyond the query ID/item ID). As a result, the model can onl
developers.google.com
전 시간: embedding을 배우는데 matrix factorization사용법
잠깐! Matrix Factorization이란?
간단한 embedding 모델. user-item의 매트릭스에 비어있는 요소를 채우는 기술.
user-item 매트릭스는 실제로 결측치가 매우 많기에 결측치를 채우기 위해 차원을 축소해서 영화의 잠재적 특성을 찾아 결측치를 채운다. 이때 사용하는 방법은 PCA, SVD, SVD++ 같은 알고리즘으로 분해하거나 축소한다.
24를 6x4로 본다. 이처럼 user-item matrix = ( ) x ( )로 본다.

www.youtube.com/watch?v=ZspR5PZemcs
위 영상은 Matrix Factorization을 설명하는 매우 좋은 영상이므로 꼭 보기!
Matrix factorization의 한계
1) side feature 사용의 어려움(training set에 존재하는 user 혹은 item만 추천받을 수 있다.)
2) 추천의 관계성: similarity measure로서 dot product(내적)을 이용할 때 유명한 아이템들이 모두에게 추천되는 경향이 있다. → 특정 사용자의 관심사를 찾기 어렵다.
▶ Deep Neural Network(DNN) 모델은 위 문제들을 해결할 수 있다.
: 네트워크의 input layer 유연성 때문에 query feature와 item feature를 쉽게 포함하여 특정 사용자의 관심사를 찾는데 도움이 되고 추천의 관계성을 향상 시킬수 있다.
Softmax DNN for Recommendation
Softmax: 다중 클래스 분류 예측 문제에 다룬다.
- Input: user query
- Output: 확률 벡터(corpus의 item숫자와 같은 사이즈)
DNN에 해당되는 Input
- dense featrue (e.g. watch time and time since last watch)
- sparse features (e.g. watch history and country)
matrix factorization 접근방법과 다르게, side features(e.g. 나이, 나라)를 더할 수 있다.
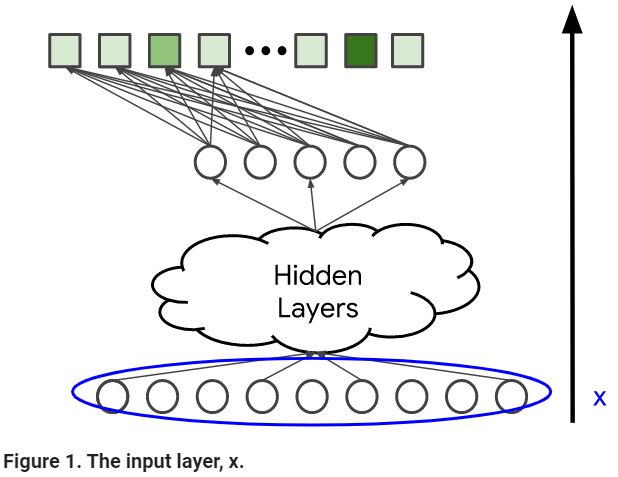
Model 아키텍처
: 모델의 복잡성과 표현성을 결정한다.
hidden layer와 non-linear activation function(e.g. ReLU)를 더함으로서, 모델은 데이터의 더 복잡한 관계를 잡을 수 있다.
하지만, 파라미터의 수를 늘리는 것은 모델이 훈련하기 더 어렵고 비싸다.

Softmax Output: Predicted Probability Distribution

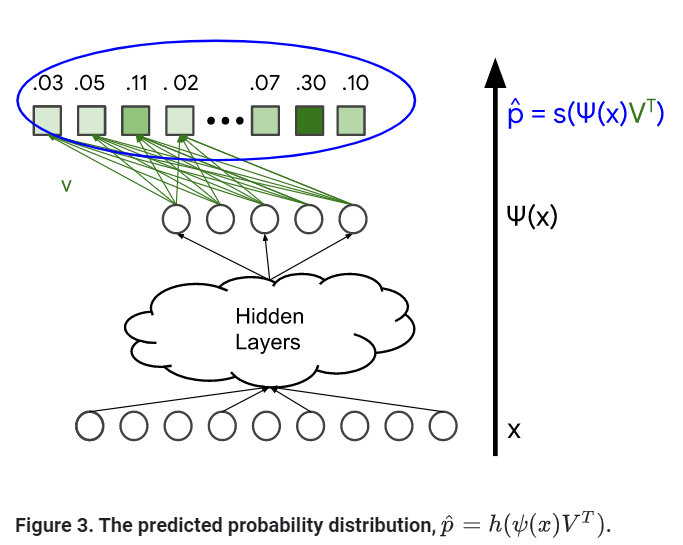
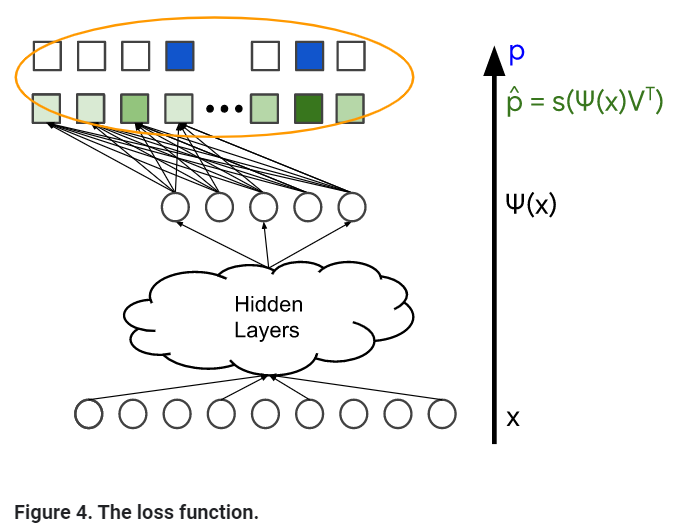
Loss Function
p_hat: softmax layer의 결과(확률 분포)
p: ground truth; user와 관련있는 items. Normalized multi-hot distribution으로 표현될 수 있다.(확률 벡터)
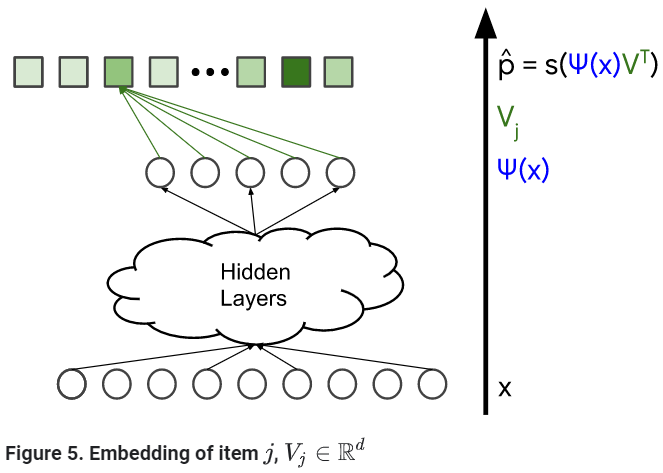
Softamx Embeddings
아이템 j의 확률: p_hat_j = exp(<프사이(x), V_j>) / Z (* Z: 정규화 상수)
다른 말로, log(p_hat_j) = <프사이(x), V_j> - log(Z)로, d차원의 두 벡터 내적이라 할 수 있다.
query와 item embedding으로 해석 가능:

DNN and Matrix Factorization
Softmax 모델과 matrix factorization모델의 공통점
아이템당 embedding 벡터 하나를 배운다.
→ matrix factorization에서 item embedding matrix라고 불리는 것은 softmax layer의 가중치 matrix이다.
차이점
Matix Factorization: query당 하나의 embedding을 배운다.
Softmax 모델: query feature인 x로부터 embedding 프사인(x)로의 맵핑을 배운다.
▶ query side를 nonlinear function 프사인으로 대체한다는 점에서, DNN 모델을 matrix factorizaion을 일반화한 모델이라고 생각할 수 있다.
Item Features도 위와 같은 방법으로 사용가능하다.
대신, two-tower neural network가 필요하다.
1) query features(x_query)를 query embedding(프사인(x_query))로 맵핑하는 NN
2) item features(x_item)를 item embedding(파이(x_item))로 맵핑하는 NN
모델의 output 은 <프사인(x_query), 파이(x_item)>이다.
▶ 이건 softmax model이 아니다. (∵ x_query에 해당하는 확률 벡터 대신 (x_query, x_item)당 하나의 값을 예측하기 때문이다.)