AI_ML
DKT란?
썬2
2022. 4. 20. 17:31
DKT
- 학생들의 반응을 예측하는 문제에 RNN과 LSTM 모델을 적용시킨 방법
- 학생의 과거 학습 활동 데이터를 이용하여 시간이 지남에 따라 학생의 지식 상태(knowleddge state)를 모델링.
RNN 모델의 이점
- 인간 도메인 지식에 명시적 인코딩 없이 복잡한 표현 가능.
NN 모델로서의 이점
- 다양한 knowledge tracking data set에서 예측 성능이 크게 향상
- 학습된 모델은 지능형 커리큘럼 설계에 사용 가능
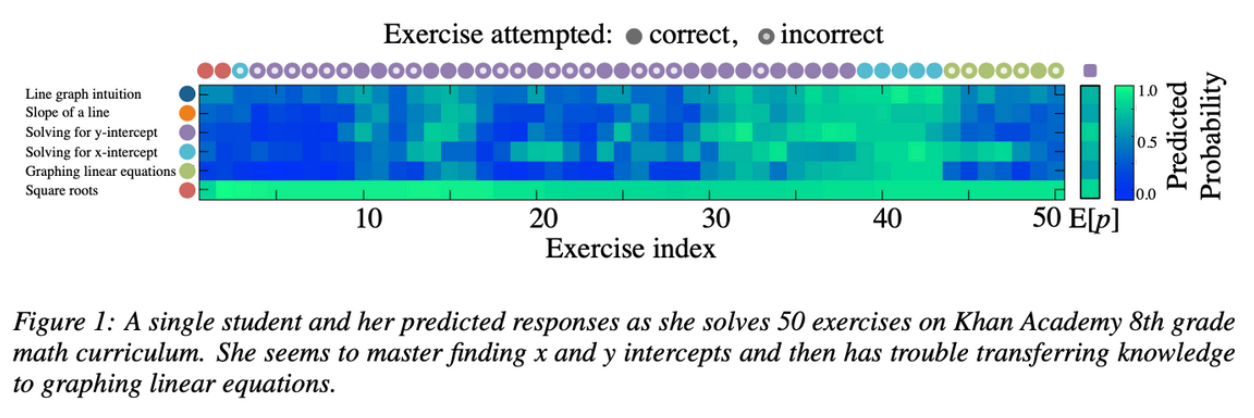
한 학생이 50개 문제를 풀 때 나온 예측 정답률를 그림으로 나타냄. (안에 색이 있으면 맞춘 문제. 안에 색이 없으면 틀린 문제.) y-intercept를 10번에서 맞추니 조금 초록색이 되었다.
지식 상태 표현 방법

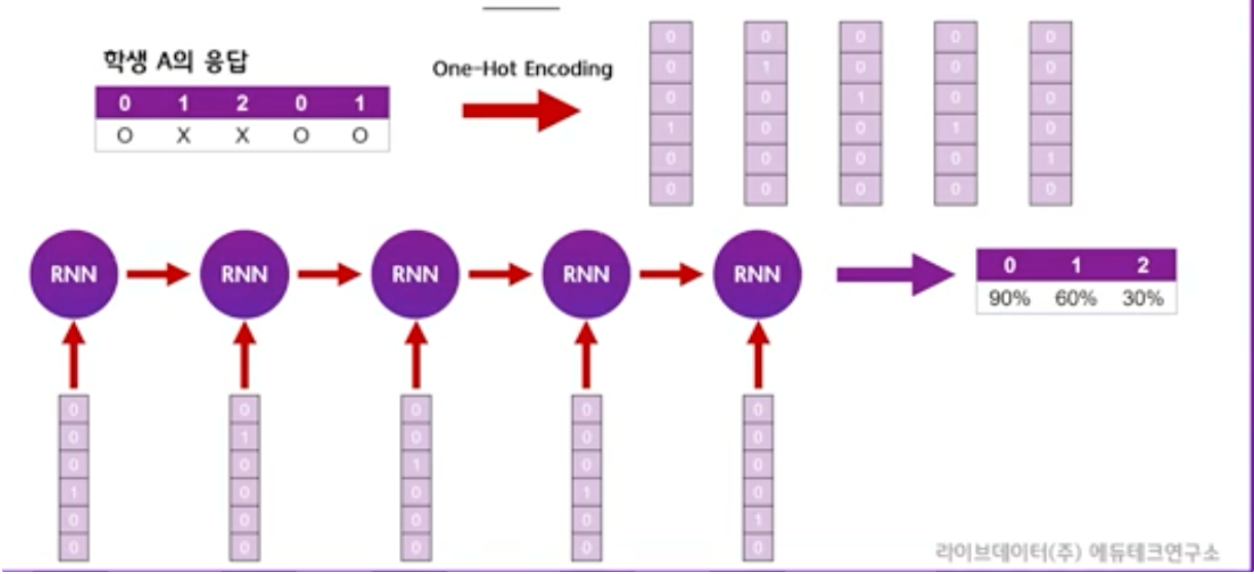
x: 학생의 행동에 대해 원핫인코딩이나 압축된 표현. (학생들의 정답여부를 인코딩한 값)
y: 데이터셋의 문제가 맞을 확률을 나타낸 벡터. (예측값)
실생활에 활용 방법
커리큘럼 최적화 가능.
정오답 예측 확률을 활용하여 문제간의 관계 파악 가능. (하지만 인간이 정의한 문제 유형보다는 정확성이 떨어짐.)
한계 및 문제점 (DKT+ 등장 배경)
한계: 데이터 양에 의존(대량의 훈련 데이터와 균형된 데이터가 필요하다.)
- DKT가 관측한 현 시점의 데이터를 reconstruct 할 수 없다.
- 인간의 직관: A 문제를 맞추었다면 다음에도 맞추기 쉽고 틀렸다면 다음번에도 틀릴 가능성의 크다.
- 그런데 DKT는 이를 잘 따르지 못한다.
- 왜냐: 다음 문제의 정답 여부에만 의존하기 때문. (A 문제가 연달아 등장한 기록이 없을 때 발생) → reconstruciton error term 제시: 문제 q를 반복 했을 때 현재 정답 여부 a를 반복하는 경향을 갖도록.
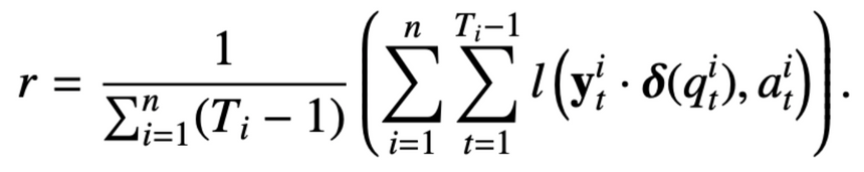
- 예측 결과 y가 시간에 따라 지나치게 요동치는 현상(way transition)
- 인간의 직관: 학습자의 지식이 서서히 변화한다.
- 그런데 DKT는 이를 잘 따르지 못한다.
- 왜냐: 현재 시점의 interaction 정보에 의해 DKT가 추정하는 knowledge state가 크게 변화해서. (RNN 구조의 본질적 문제) → 연속한 예측값 y와 y+1의 차이 컨트롤 하는 loss: w1-L1 loss, w2-L2 loss

최종 Loss:
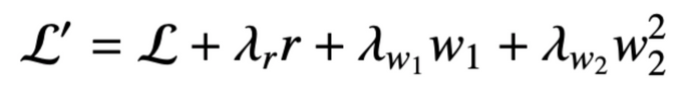
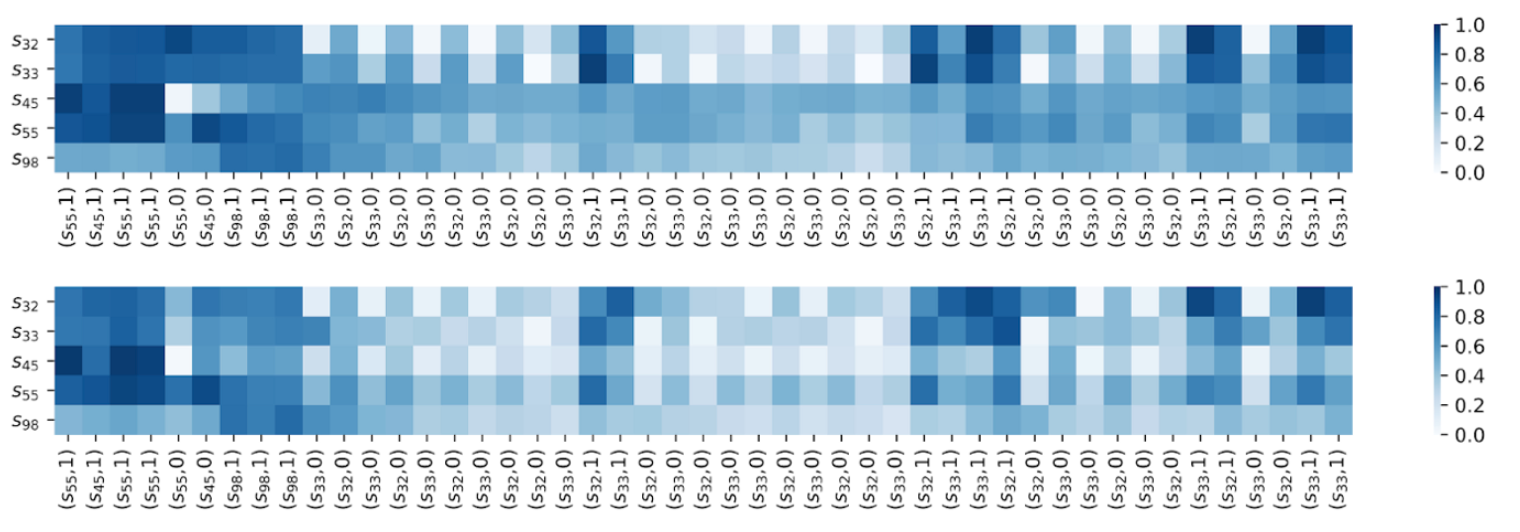
+) DKT+가 DKT보다 일관성 있다는 결과를 보여줌.
- 아래인 DK보다 위 그림인 DKT+가 s45, s55, s98에서 안정적인 그림을 보여준다. → RNN의 hidden layer에 저장된 학생의 knowledge state가 현재 시점의 input에 과하게 의존하는 문제를 어느정도 해소.
데이터 문제 극복 방법 (데이터 클래스 균형 맞추기)
- under sampling / over sampling → 적합한 방법X
- 적은 샘플에는 더 높은 cost 할당. 람다가 클수록 적은 샘플에 더 focus

- 전문가의 지식 이용
- Attentional Hidden State: DKT의 hidden state와 전문가가 구성한 context vector를 concatenation layer를 사용하여 결합.
참고:
https://www.youtube.com/watch?v=GArTg8bJtuo
https://www.youtube.com/watch?v=nknWT8PLiyo
https://www.upstage.ai/events/tech-talks/deep-knowledge-tracing